10 Bibliotecas Python Essenciais Para Criar Aplicações com LLMs em 2026
Introdução
Criar aplicações com LLMs em 2026 vai muito além de abrir o ChatGPT, o Claude ou o Codex e enviar um prompt. Esses modelos são a parte mais visível da experiência, mas uma aplicação real de IA generativa precisa de uma camada técnica bem maior: carregar modelos, conectar documentos, montar fluxos de RAG, chamar APIs, criar agentes de IA, ajustar modelos com fine-tuning, avaliar respostas, observar falhas e fazer deploy com segurança.
Na prática, um produto com inteligência artificial costuma combinar várias ferramentas. Um chatbot interno pode usar LlamaIndex para consultar PDFs, LangChain para ligar modelos e ferramentas, OpenAI Python SDK para chamar uma API de modelo, DeepEval para medir a qualidade das respostas e FastAPI para expor tudo como um serviço. Já uma empresa que quer rodar modelos locais pode adicionar vLLM para servir modelos open-source com mais desempenho.
Este artigo apresenta 10 bibliotecas Python para LLMs que ajudam desenvolvedores, estudantes e entusiastas a sair do protótipo e criar aplicações com LLMs mais próximas do mundo real.
1. Transformers
A biblioteca Transformers, da Hugging Face, é uma das bases mais importantes do ecossistema de modelos open-source. Ela permite carregar modelos pré-treinados, usar tokenizadores, gerar texto, classificar conteúdo, fazer sumarização, trabalhar com modelos multimodais e realizar fine-tuning de LLMs para tarefas específicas.
Ela é muito útil quando você quer ter controle direto sobre o modelo, o tokenizer, os parâmetros de geração e o processo de treino. Em vez de depender apenas de uma API fechada, o desenvolvedor pode testar modelos como Llama, Mistral, Qwen, Gemma e outros modelos disponíveis no Hugging Face Hub, respeitando licenças e requisitos de hardware.
Exemplo de uso
Um uso simples seria carregar um modelo open-source para gerar respostas em um ambiente local ou em um servidor com GPU.
from transformers import pipeline
gerador = pipeline("text-generation", model="Qwen/Qwen3-0.6B")
resposta = gerador("Explique RAG em linguagem simples:", max_new_tokens=120)
print(resposta[0]["generated_text"])Para projetos maiores, Transformers costuma aparecer junto com PEFT, Accelerate, bitsandbytes, datasets e ferramentas de monitoramento de treino.
2. LangChain
LangChain é uma biblioteca para orquestrar aplicações com LLMs. Ela ajuda a conectar prompts, modelos, ferramentas, APIs, bancos vetoriais, documentos, retrievers e fluxos multi-etapas. Em vez de escrever toda a cola entre esses componentes do zero, o desenvolvedor usa interfaces prontas para montar a aplicação.
O ecossistema LangChain possui muitas integrações para Python, incluindo chat models, embedding models, retrievers, vector stores, document loaders, tools e toolkits. Isso facilita trocar de provedor, ligar um modelo a uma ferramenta externa ou montar uma pipeline de RAG sem reescrever toda a arquitetura.
Exemplo de uso
LangChain é útil para criar um assistente que recebe uma pergunta, consulta documentos, chama uma API externa e devolve uma resposta estruturada. Também é uma boa porta de entrada para quem quer entender agentes de IA com ferramentas.
from langchain.agents import create_agent
def buscar_status_pedido(codigo: str) -> str:
return f"Pedido {codigo}: em transporte."
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[buscar_status_pedido],
system_prompt="Você e um assistente de atendimento objetivo."
)
resultado = agent.invoke({"messages": [{"role": "user", "content": "Status do pedido 123?"}]})3. LlamaIndex
LlamaIndex é uma das bibliotecas mais fortes para RAG, bases de conhecimento e aplicações que precisam conectar LLMs a dados privados. Ela ajuda a carregar documentos, dividir conteúdo em partes menores, criar índices, conectar bancos vetoriais, montar query engines e transformar dados em contexto útil para o modelo.
Se a sua aplicação precisa responder perguntas sobre PDFs, manuais, páginas internas, bases SQL, arquivos locais ou documentos de uma empresa, LlamaIndex costuma ser uma escolha muito natural. Ele foi desenhado para o problema de context augmentation: dar ao LLM acesso ao contexto certo no momento da pergunta, sem precisar treinar o modelo novamente.
Exemplo de uso
Um exemplo clássico é criar um chatbot que responde perguntas sobre arquivos dentro de uma pasta.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documentos = SimpleDirectoryReader("documentos").load_data()
indice = VectorStoreIndex.from_documents(documentos)
consulta = indice.as_query_engine()
resposta = consulta.query("Quais são os principais pontos do contrato?")
print(resposta)Esse tipo de fluxo é a base de muitos sistemas de RAG usados em suporte, jurídico, educação, vendas técnicas e documentação interna.
4. vLLM
vLLM é uma biblioteca voltada para inferência e serving de LLMs open-source com alta performance. Ela é usada quando o problema deixa de ser apenas “testar um modelo” e passa a ser “servir um modelo para vários usuários com menor latência e maior vazão”.
O vLLM ficou conhecido por técnicas como gerenciamento eficiente de memória de atenção, batching contínuo e servidor compatível com APIs no estilo OpenAI. Isso permite rodar um modelo local ou em nuvem e chamá-lo de forma parecida com uma API de chat.
Exemplo de uso
Você pode servir um modelo local com vLLM e acessá-lo usando um cliente HTTP ou até o cliente Python da OpenAI apontando para a URL local.
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-localfrom openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-local",
)
resposta = client.chat.completions.create(
model="NousResearch/Meta-Llama-3-8B-Instruct",
messages=[{"role": "user", "content": "Explique inferência local com LLMs."}],
)
print(resposta.choices[0].message.content)Para equipes que querem reduzir dependência de APIs externas, controlar dados sensíveis ou otimizar custo por token em escala, vLLM pode ser uma peça central da arquitetura.
5. Unsloth
Unsloth ajuda no fine-tuning eficiente de LLMs, principalmente com técnicas como LoRA e QLoRA. A ideia é tornar o ajuste de modelos mais acessível, reduzindo a necessidade de VRAM e simplificando notebooks e fluxos de treino.
Fine-tuning não deve ser a primeira resposta para todo problema. Muitas vezes, RAG resolve melhor quando o objetivo é consultar conhecimento atualizado ou privado. Mas quando você precisa ajustar estilo, formato, comportamento, domínio ou uma tarefa repetitiva muito específica, Unsloth pode acelerar o caminho.
Exemplo de uso
Um time de suporte técnico pode usar Unsloth para ajustar um modelo open-source com exemplos reais de perguntas e respostas, fazendo o modelo aprender o tom, a estrutura e as políticas de atendimento da empresa. Com QLoRA, esse processo tende a exigir menos memória do que o ajuste completo dos pesos do modelo.
6. CrewAI
CrewAI permite criar equipes de agentes de IA com papéis diferentes. Em vez de ter um único agente tentando fazer tudo, você pode definir um pesquisador, um redator, um analista, um revisor e um executor, cada um com objetivo, contexto e ferramentas próprias.
Esse modelo é interessante para fluxos em que o trabalho tem etapas claras. Por exemplo: pesquisar informações, organizar dados, gerar um relatório, revisar consistência e enviar o resultado para uma API. A biblioteca trabalha com conceitos como agents, tasks, crews e processos sequenciais ou hierárquicos.
Exemplo de uso
Uma equipe de agentes pode automatizar a produção de um briefing: o agente pesquisador coleta dados, o analista resume padrões, o redator cria o texto final e o revisor verifica se as instruções foram seguidas.
from crewai import Agent, Task, Crew, Process
pesquisador = Agent(role="Pesquisador", goal="Coletar informações confiáveis")
redator = Agent(role="Redator", goal="Transformar achados em texto claro")
tarefa = Task(
description="Criar um resumo didático sobre RAG para iniciantes.",
expected_output="Resumo em português com exemplos práticos.",
agent=redator,
)
crew = Crew(
agents=[pesquisador, redator],
tasks=[tarefa],
process=Process.sequential,
)
resultado = crew.kickoff()7. AutoGPT
AutoGPT foi um dos projetos que popularizou a ideia de agentes autônomos orientados a objetivos e tarefas multi-etapas. O conceito chamou atenção porque mostrava um agente capaz de quebrar um objetivo em passos menores, executar ações, observar resultados e continuar iterando.
Em 2026, AutoGPT deve ser entendido mais como uma referência importante do movimento de agentes autônomos do que como a única opção para novos projetos. O próprio ecossistema evoluiu: existem frameworks mais modulares, plataformas de automação, ferramentas de avaliação e formas mais controladas de construir agentes em produção.
Exemplo de uso
AutoGPT é útil para estudar padrões de agentes orientados a objetivos, automações longas, execução de tarefas com ferramentas e benchmarks de agentes. Para produção, vale comparar com alternativas mais recentes e com bibliotecas que oferecem maior controle de estado, memória, permissões e observabilidade.
8. LangGraph
LangGraph permite construir fluxos com estado, memória, ramificações, persistência e controle mais avançado para agentes de IA. Enquanto LangChain é muito usado para montar componentes e agentes de forma mais direta, LangGraph entra quando o fluxo precisa ser mais previsível e controlado.
Ele é especialmente útil para agentes long-running, workflows com human-in-the-loop, passos que podem falhar e retomar depois, memória de curto e longo prazo, verificações intermediárias e controle explícito do caminho que o agente pode seguir.
Exemplo de uso
Imagine um agente financeiro interno. Ele pode receber uma pergunta, classificar o tipo de solicitação, consultar documentos, pedir aprovação humana antes de executar uma ação sensível e só depois chamar uma API. LangGraph ajuda a modelar esse fluxo como um grafo, com nós, estado e transições.
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
class Estado(TypedDict):
pergunta: str
resposta: str
def responder(estado: Estado):
return {"resposta": f"Resposta para: {estado['pergunta']}"}
grafo = StateGraph(Estado)
grafo.add_node("responder", responder)
grafo.add_edge(START, "responder")
grafo.add_edge("responder", END)
app = grafo.compile()
print(app.invoke({"pergunta": "O que e LangGraph?"}))9. DeepEval
DeepEval serve para testar e avaliar aplicações com LLMs. Ele ajuda a medir qualidade de respostas, relevância, fidelidade ao contexto, alucinação, desempenho de RAG, comportamento de agentes e regressão entre versões de prompts, modelos ou pipelines.
Esse ponto é essencial: aplicações com IA generativa não devem ser avaliadas apenas no “parece bom”. Um sistema de RAG pode dar uma resposta fluente e ainda assim inventar informações. Um agente pode chamar ferramentas, mas não concluir a tarefa. DeepEval permite criar testes mais próximos do ciclo de engenharia, inclusive com integração a Pytest e CI/CD.
Exemplo de uso
Um time pode criar casos de teste com perguntas, respostas esperadas e contexto recuperado. Depois, mede se a resposta foi fiel ao contexto e relevante para a pergunta.
from deepeval import evaluate
from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
caso = LLMTestCase(
input="Qual é a política de reembolso?",
actual_output="Clientes podem pedir reembolso em até 30 dias.",
retrieval_context=["A política permite reembolso em até 30 dias após a compra."],
)
metric = FaithfulnessMetric(threshold=0.7)
evaluate(test_cases=[caso], metrics=[metric])10. OpenAI Python SDK
O OpenAI Python SDK é uma das formas mais diretas de integrar modelos da OpenAI em aplicações Python. Ele pode ser usado para chatbots, automações, agentes, análise de documentos, classificação, extração de dados, geração de conteúdo e chamadas com ferramentas.
Para quem está começando, o SDK é uma excelente porta de entrada porque reduz a complexidade inicial. Você não precisa hospedar um modelo, configurar GPU ou lidar com otimização de inferência. Basta criar uma chave de API, instalar a biblioteca e chamar o modelo adequado ao seu caso.
Exemplo de uso
Um exemplo simples com a Responses API:
from openai import OpenAI
client = OpenAI()
resposta = client.responses.create(
model="gpt-4.1-mini",
input="Explique RAG em três frases para um iniciante."
)
print(resposta.output_text)Em projetos reais, o OpenAI Python SDK pode trabalhar junto com LlamaIndex, LangChain, LangGraph, DeepEval, bancos vetoriais e APIs internas.
Tabela comparativa das bibliotecas
| Biblioteca | Melhor uso | Exemplo prático | Nível de dificuldade |
|---|---|---|---|
| Transformers | Carregar modelos open-source, tokenização, geração e fine-tuning | Rodar um modelo local para gerar texto ou ajustar um modelo com dados próprios | Intermediário a avançado |
| LangChain | Orquestrar LLMs, ferramentas, APIs, documentos e vector stores | Assistente que consulta documentos e chama uma API externa | Intermediário |
| LlamaIndex | RAG, bases de conhecimento e consulta a dados privados | Chatbot que responde perguntas sobre PDFs e documentos internos | Iniciante a intermediário |
| vLLM | Servir modelos locais ou open-source com alta performance | Expor um modelo Llama ou Qwen em um endpoint compatível com OpenAI | Avançado |
| Unsloth | Fine-tuning eficiente com LoRA e QLoRA | Ajustar um modelo para atendimento técnico ou formato específico | Intermediário a avançado |
| CrewAI | Equipes de agentes com papéis, tarefas e processos | Fluxo com pesquisador, redator, analista e revisor | Intermediário |
| AutoGPT | Estudar agentes autônomos e tarefas multi-etapas orientadas a objetivo | Automação que quebra um objetivo em subtarefas e executa ações | Intermediário a avançado |
| LangGraph | Agentes com estado, memória, ramificações e controle de fluxo | Workflow com aprovação humana antes de executar uma ação sensível | Intermediário a avançado |
| DeepEval | Avaliar respostas, RAG, agentes, alucinação e regressão | Teste automatizado para verificar se a resposta está fiel ao contexto | Intermediário |
| OpenAI Python SDK | Integrar modelos da OpenAI em apps Python | Chatbot, extrator de dados, automação ou gerador de conteúdo | Iniciante |
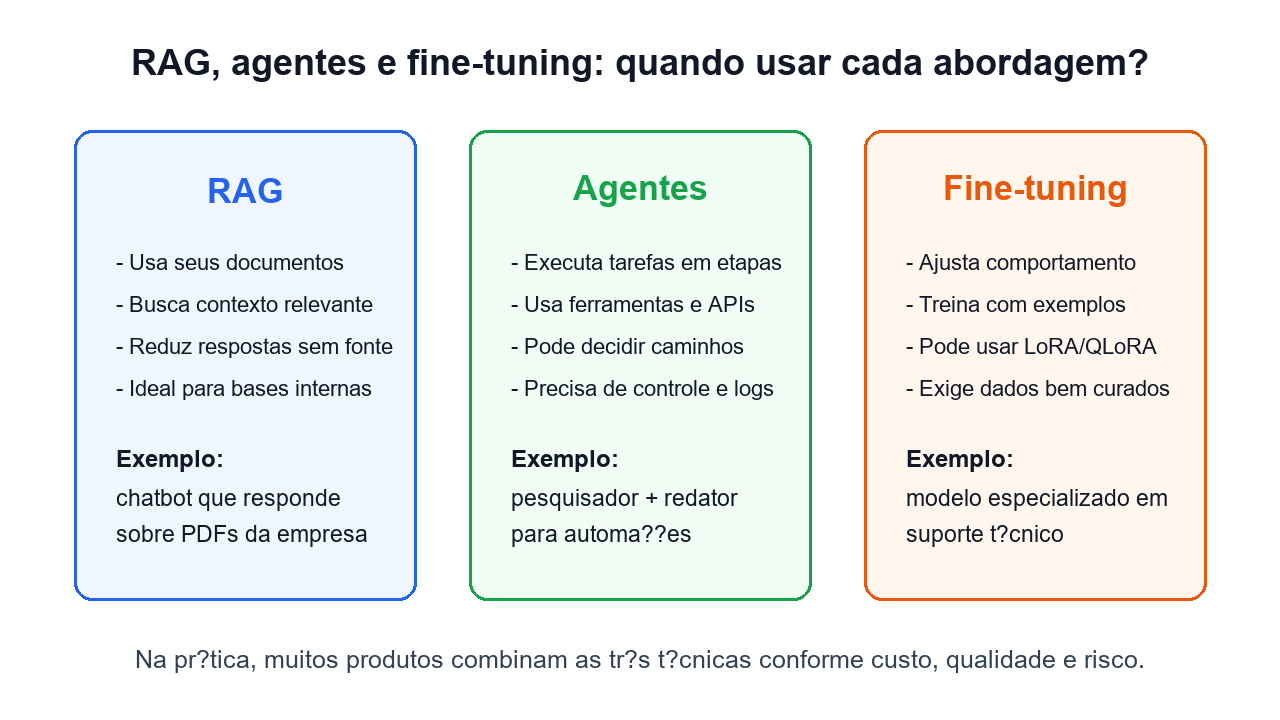
Qual biblioteca escolher para cada projeto?
A melhor escolha depende do objetivo do projeto. Não existe uma única biblioteca perfeita para todos os cenários.
- Para RAG com documentos: use LlamaIndex ou LangChain. LlamaIndex tende a ser muito forte quando o foco principal é conectar dados privados ao LLM. LangChain é interessante quando o RAG faz parte de um fluxo maior com ferramentas e APIs.
- Para agentes: use CrewAI ou LangGraph. CrewAI é mais direto para equipes de agentes com papéis. LangGraph é melhor quando você precisa de estado, memória, ramificações, retomada e controle fino.
- Para fine-tuning: combine Unsloth com Transformers. Unsloth facilita LoRA e QLoRA, enquanto Transformers continua sendo uma base importante para carregar modelos, tokenizers e pipelines.
- Para servir modelos locais: use vLLM. Ele é indicado quando você precisa expor modelos open-source com desempenho, batching e API compatível com clientes já conhecidos.
- Para avaliar qualidade: use DeepEval. Ele ajuda a transformar qualidade de LLM em testes repetíveis, especialmente em RAG e agentes.
- Para começar rápido com API: use OpenAI Python SDK. É o caminho mais simples para construir um primeiro chatbot, automação ou analisador de documentos.
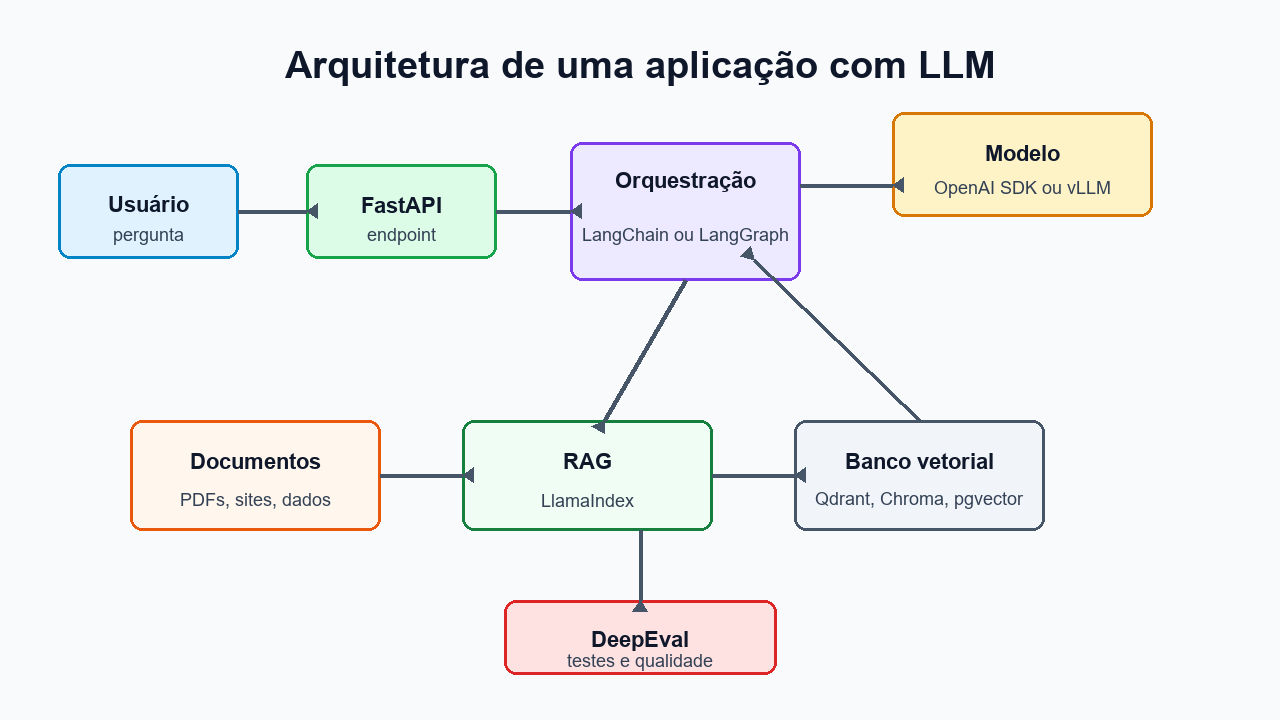
Exemplo de stack para um projeto real
Imagine um assistente de IA para uma empresa que precisa responder perguntas sobre políticas internas, consultar documentos e executar pequenas automações. Uma stack realista poderia ser:
- Python como linguagem principal.
- LlamaIndex para carregar PDFs, páginas internas e documentos da empresa.
- LangChain ou LangGraph para orquestrar o fluxo, decidir quando consultar documentos e quando chamar ferramentas.
- OpenAI Python SDK para usar modelos via API ou vLLM para rodar um modelo local open-source.
- DeepEval para testar fidelidade ao contexto, relevância e regressão entre versões.
- FastAPI para expor a aplicação como API.
- Qdrant, Chroma ou pgvector como banco vetorial para armazenar embeddings e recuperar contexto.
Essa arquitetura permite evoluir por etapas. Primeiro você cria um chatbot simples. Depois adiciona documentos. Em seguida, mede qualidade. Por fim, inclui agentes, permissões, logs, observabilidade e deploy em produção.
Por onde começar?
Para iniciantes, o melhor caminho é evitar tentar aprender tudo ao mesmo tempo. Uma trilha simples seria:
- Aprender Python básico: funções, listas, dicionários, ambientes virtuais, pacotes e requisições HTTP.
- Testar o OpenAI Python SDK para entender como chamar um modelo via API.
- Criar um chatbot simples no terminal ou em uma pequena API.
- Adicionar RAG com LlamaIndex usando uma pasta de documentos.
- Criar agentes com CrewAI para entender papéis, tarefas e colaboração entre agentes.
- Avaliar com DeepEval para medir se as respostas estão boas de verdade.
- Fazer deploy com FastAPI, adicionando logs, controle de erros e limites de uso.
Depois dessa base, fica mais fácil explorar LangGraph para fluxos com estado, Transformers para modelos open-source e Unsloth para fine-tuning de LLMs.
Boas práticas para aplicações com LLMs
Antes de escolher qualquer biblioteca, vale lembrar alguns princípios:
- Comece simples: uma API com prompt bem feito pode validar a ideia antes de uma arquitetura complexa.
- Use RAG antes de fine-tuning quando o problema for conhecimento: documentos mudam com frequência e podem ser atualizados sem treinar o modelo.
- Avalie desde cedo: sem testes, é difícil saber se uma mudança melhorou ou piorou a aplicação.
- Controle ferramentas de agentes: agentes devem ter permissões claras, logs e limites, principalmente quando chamam APIs externas.
- Monitore custo e latência: aplicações com LLMs podem ficar caras ou lentas sem cache, batching e escolha correta de modelo.
- Proteja dados sensíveis: revise o que é enviado para APIs externas e quando faz sentido usar modelos locais.
Conclusão
As bibliotecas Python para LLMs amadureceram muito. Hoje, criar aplicações com LLMs envolve mais do que escrever prompts: é preciso conectar dados, organizar fluxos, avaliar qualidade, integrar APIs, controlar agentes, ajustar modelos e pensar em deploy.
Transformers, LangChain, LlamaIndex, vLLM, Unsloth, CrewAI, AutoGPT, LangGraph, DeepEval e OpenAI Python SDK resolvem partes diferentes desse quebra-cabeça. A escolha certa depende do objetivo: RAG, agentes de IA, fine-tuning de LLMs, inferência local, API, avaliação ou produção.
O mais importante é entender que não existe uma biblioteca perfeita para todos os casos. O ideal é combinar ferramentas conforme a necessidade real do projeto, mantendo a arquitetura simples o suficiente para evoluir com segurança.
Agora quero saber de você: qual dessas bibliotecas você já usa ou quer aprender primeiro? Deixe seu comentário e compartilhe sua experiência.


Publicar comentário